




合作客戶/
拜耳公司 |
同濟大學 |
聯(lián)合大學 |
美國保潔 |
美國強生 |
瑞士羅氏 |






相關(guān)新聞Info
-
> 基于振蕩氣泡法測定聲懸浮液滴的表面張力
> 側(cè)鏈烷基的飽和度對腰果酚磺酸鹽水溶液的表面活性、界面活性的影響
> 篩選常用、經(jīng)濟且可抑制低階煤煤塵的表面活性劑(三)
> 水性油墨的基本配方及成分
> 納米氧化鋁可提高BOPP薄膜表面張力,增強薄膜印刷適用性
> 磁場強度和磁化時長對除草劑溶液表面張力、噴霧霧滴粒徑的影響(二)
> 應用熒光顯微鏡研究了蛋白質(zhì)在氣-水界面的組裝——結(jié)論、致謝!
> 定性分析聚合物界面張力與系統(tǒng)黏度比之間的關(guān)系——數(shù)值模擬、實驗研究結(jié)果
> 從哪些方面可以體現(xiàn)出酶特異性地結(jié)合某種物質(zhì)?
> 表面張力儀鉑金環(huán)、鉑金板兩種測試方法的不同
推薦新聞Info
-
> 不同質(zhì)量濃度、pH、鹽度對三七根提取物水溶液表面張力的影響(三)
> 不同質(zhì)量濃度、pH、鹽度對三七根提取物水溶液表面張力的影響(二)
> 不同質(zhì)量濃度、pH、鹽度對三七根提取物水溶液表面張力的影響(一)
> 氟硅表面活性劑(FSS)水溶液表面張力、發(fā)泡力、乳化力測定(三)
> 氟硅表面活性劑(FSS)水溶液表面張力、發(fā)泡力、乳化力測定(二)
> 氟硅表面活性劑(FSS)水溶液表面張力、發(fā)泡力、乳化力測定(一)
> 不同配方的水性氟丙樹脂涂料涂膜合成、性能指標
> 芬蘭Kibron表面張力測試儀跟蹤氯乙烯懸浮聚合中的表面張力變化情況
> 泡泡消煙原理,不同質(zhì)量分數(shù)堿劑發(fā)泡液表面張力的測試結(jié)果
> 什么是超微量天平,超微量天平使用方法、最小稱量值
基于遺傳算法優(yōu)化提高界面張力的預測速度和精度
來源:北京科技大學 瀏覽 502 次 發(fā)布時間:2024-06-06
準確預測鹽水-氣體界面張力對于優(yōu)化儲層中氣體的分布和運移至關(guān)重要。這有助于減少氣體泄漏風險、提高儲存容量,并保障地下氣體儲存的長期穩(wěn)定性,同時推動清潔能源發(fā)展和減少碳排放。然而,目前預測界面張力的方法(如實驗法)存在耗時、費力、成本高以及難以表征多組分氣體共同影響的問題。此外,在鹽水-多組分氣體(如H2,CH4,CO2等)界面張力方面,缺乏準確的數(shù)學表達式。
近年來,機器學習算法顯示出了良好的預測潛力。在眾多機器學習方法中,自動機器學習(AutoML)算法可處理具有多個因素的復雜預測任務(wù),適用于鹽水-多組分氣體界面張力的預測問題。符號回歸(SR)可通過數(shù)據(jù)生成相應的數(shù)學表達式,從而為機器學習模型提供可解釋性。然而,這兩種方法在訓練和發(fā)現(xiàn)過程中非常耗時,需要一種先進的算法來提高效率。遺傳算法(GA)是一種生物啟發(fā)式算法,具有高效的全局搜索能力,可用于解決優(yōu)化問題,從而提高模型開發(fā)和應用的效率。
因此,本文提供了一中基于遺傳算法優(yōu)化的自動機器學習和符號回歸模型(GA-AutoML-SR),以準確預測鹽水-氣體界面張力,并生成相應的數(shù)學表達式。
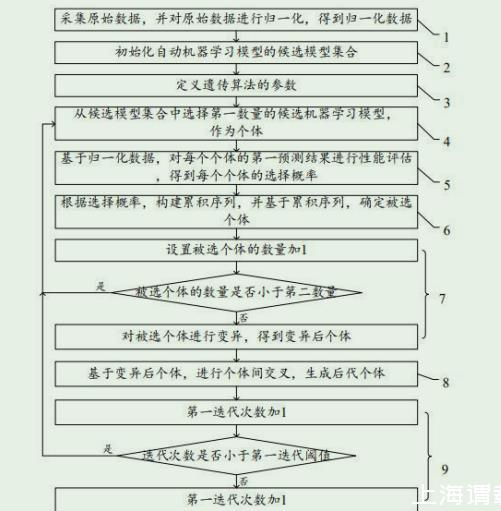

遺傳算法優(yōu)化的界面張力智能預測方法
采集原始數(shù)據(jù),并對所述原始數(shù)據(jù)進行歸一化,得到歸一化數(shù)據(jù);
初始化自動機器學習模型的候選模型集合,所述候選模型集合包括多個候選機器學習模型;
定義遺傳算法的參數(shù);
從所述候選模型集合中選擇第一數(shù)量的候選機器學習模型,作為個體;
基于所述歸一化數(shù)據(jù),對每個所述個體的第一預測結(jié)果進行性能評估,得到每個所述個體的選擇概率;
根據(jù)所述選擇概率,構(gòu)建累積序列,并基于所述累積序列,確定被選個體;
設(shè)置所述被選個體的數(shù)量加1,并判斷所述被選個體的數(shù)量是否小于第二數(shù)量,若是,跳轉(zhuǎn)至從所述候選模型集合中選擇第一數(shù)量的候選機器學習模型步驟;若否,對所述被選個體進行變異,得到變異后個體;
基于所述變異后個體,進行個體間交叉,生成后代個體;
第一迭代次數(shù)加1,并判斷第一迭代次數(shù)是否小于第一迭代閾值,若是,跳轉(zhuǎn)至從所述候選模型集合中選擇第一數(shù)量的候選機器學習模型步驟;若否,將當前所述后代個體作為預測模型;
基于所述原始數(shù)據(jù),生成多組樣本數(shù)據(jù),并對所述樣本數(shù)據(jù)進行歸一化,得到歸一化樣本;
將所述歸一化樣本輸入所述預測模型,得到第二預測結(jié)果;
將所述第二預測結(jié)果和所述歸一化樣本作為補充數(shù)據(jù)集,合并所述補充數(shù)據(jù)集和所述歸一化數(shù)據(jù),得到合并數(shù)據(jù);
定義表達式算子;
基于符號回歸,根據(jù)所述表達式算子和所述合并數(shù)據(jù),生成初始模型表達式;
利用遺傳算法搜索所述初始模型表達式的空間,確定候選表達式;
對所述候選表達式的適應度進行性能評估,搜索得到最優(yōu)的模型表達式。
可選地,基于所述歸一化數(shù)據(jù),對每個所述個體的第一預測結(jié)果進行性能評估,得到每個所述個體的選擇概率,具體為:
將所述歸一化數(shù)據(jù)作為所述個體的輸入,得到所述個體的第一預測結(jié)果;
采用適應度函數(shù)對所述第一預測結(jié)果進行性能評估,得到對應個體的適應度值;

可選地,根據(jù)所述選擇概率,構(gòu)建累積序列,并基于所述累積序列,確定被選個體,具體為:
順序排列所有個體的選擇概率,形成第一集合;
將第一集合中的當前值與累積序列中對應位置的前一個值的和,作為累積序列的當前值;
選擇介于0到1之間的一個值,作為判定值;
將所述累積序列中與所述判定值的距離最近的數(shù)值,作為所述被選個體。
可選地,對所述被選個體進行變異,得到變異后個體,具體為:改變所述個體的結(jié)構(gòu)或參數(shù)。
可選地,基于所述變異后個體,進行個體間交叉,生成后代個體,具體為:
分別從各個變異后個體中提取特征進行組合,生成新的特征集,作為后代個體的特征表示,得到所述后代個體。
可選地,基于所述變異后個體,進行個體間交叉,生成后代個體,具體為:
將各個變異后個體的參數(shù)進行組合,得到新的參數(shù),對所述新的參數(shù)進行訓練,得到所述后代個體。
可選地,基于所述變異后個體,進行個體間交叉,生成后代個體,具體為:
將一個變異后個體的分部,結(jié)合到另一個不同的變異后個體的決策邊界中,創(chuàng)建具有新結(jié)構(gòu)個體,作為所述后代個體。
可選地,對所述候選表達式的適應度進行性能評估,搜索得到最優(yōu)的模型表達式,具體為:
基于所述合并數(shù)據(jù),對每個所述候選表達式的第三預測結(jié)果進行性能評估,確定被選表達式集合;
對所述被選表達式集合中的所有被選表達式進行變異,生成變異表達式;
基于所述變異表達式,進行交叉,生成后代表達式;

最終得到具體模型表達式為:
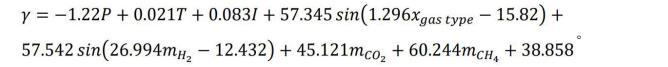
基于遺傳算法優(yōu)化的自動機器學習和符號回歸模型融合遺傳算法、自動機器學習和符號回歸方法,進行界面張力的預測,相較于傳統(tǒng)實驗測量方法,提高了界面張力的預測速度和精度,同時通過數(shù)學表達式提高了數(shù)據(jù)驅(qū)動模型的可解釋性。